摩托新手去哪练车好,杭州男子地下车库练摩托车撞400万宾利事件
727阅读

茶道六君子是泡茶的辅助工具,一共有六件,在茶席、茶桌上常见。很多人可能见过,但未必认识,甚至连名字也叫不全,更别提其来历以及正确用法了。茶道六君子看似微不足道,但在一些稍微正式的场合泡茶时,能让整个泡茶流程有条不紊,桌面更加整洁,不会出现茶叶洒落、茶渣阻塞等细节问题。来正式介绍下这个“六人”组合吧!01.茶道六君子的组...



 0
0
 807
807
 09-20 17:53
09-20 17:53
当今再无难做的生意,只有不会做生意的人!今天老师给大家分享店面十大自动吸引客流流法,做到商业模式盈利架构当中一些细小盈利点的开始!一、第一定律没有一家商店一开门就受欢迎,商店的受欢迎程度需要随着时间的推移而不断积累。事实上,老板们,你们的店不需要是做全国最好的,也不需要是做全省份最好的。你只需要成为你所在区域的最好。开...


 0
544
09-20 17:51
0
544
09-20 17:51
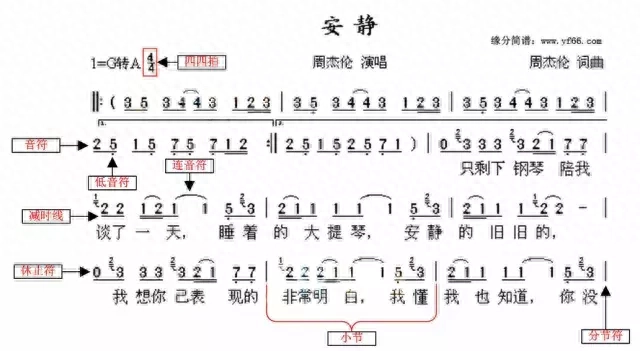
首先通过简谱可以方便的了解一些基本的乐理知识。然后,我们需要知道一些基本的五线谱元素的含义,才能更好的深入。最后,通过简谱和五线谱的对应关系,可以很方便的读懂五线谱。那么,我们开始吧!(文稍长,需要一定时间阅读和消化,大家耐心一点~)(假如你看得懂简谱,请跳过第一节)一、简谱如图1-1所示,描述了简谱中常见的元素。图1...
 0
882
09-20 17:42
0
882
09-20 17:42
生活中我们难免会碰到一些小问题,虽然这些小问题对我们没有多大的影响,但慢慢累积的话可能会成大问题,所以日常生活中这二十个冷门的小知识还是有必要知道的。20个冷门小知识1、吃了辣的东西,感觉就要被辣死了,就往嘴里放上少许盐,含一下,吐掉,漱下口,就不辣了。2、牙齿黄,可以把花生嚼碎后含在嘴里,并刷牙三分钟,很有效。3、若...


 0
526
09-20 17:38
0
526
09-20 17:38
下属从不抱怨,看似和平友爱、风平浪静的部门就是好部门吗?名牌大学毕业生就一定会成为优秀员工吗?当提拔的人表现没有达到期望的良好水平时,我们该怎么办呢?当时为什么会看错人呢?这仅是一次误判吗?以下,Enjoy:常识君|有话说01不理解不等于不放飞上司若总是优先管理,就容易倾向于压制部下的抱怨和不满情绪。部下不抱怨,别人就...


 0
613
09-20 17:33
0
613
09-20 17:33
“国学热”,一场与学术无关的盛宴。许多学者呼吁不要忘本,提倡学习中国传统文化,加上各种宣传,激起了社会大众学习中国传统文化的热情。20多年过去,我们更应该冷静地想一想,在持续的国学热背后,隐含着怎样的力量。到底什么是国学?什么是国学经典?当下如火如荼的国学教育,其主要内容是什么?随着改革开放不断深入,在各个方面取得了举...


 0
659
09-19 20:24
0
659
09-19 20:24
随着科技的发展,自媒体行业的兴起,相机慢慢走进了大众的视野。不过在很多人眼里,学习摄影是一件很烧钱的事儿,高昂的相机价格让很多喜爱摄影的人都望而却步。其实摄影真没大家想象的那么烧钱。摄影本身就是一门艺术,可以用来陶冶情操、培养气质,而且学习摄影还有很多你意想不到的收获,为什么不尝试了解学习一下呢?1、相机不贵,却可以让...


 0
983
09-19 20:21
0
983
09-19 20:21
海量知识与经济结合爆发价值效应自从2015年罗振宇在北京水立方开讲《时间的朋友》,提到了知识是第四大商业交易入口,加上罗胖耕耘知识领域的成功,之后,知识经济这个词逐渐被大众所知。依托于微信公众号、头条的自媒体在近几年也是风生水起,一时,大江南北掀起一股内容创业的热潮,知识分子和拥有制造内容能力的人也感觉到知识变现的春天...


 0
886
09-19 20:13
0
886
09-19 20:13
关于学习知识的一些想法今天和一个朋友,聊了聊关于这方面的内容。首先关于学习的内容:一定要学习能让自己有所成长的内容和知识比如说:编程你学会了以后,你会发现,你又打开了一个新的世界的大门。这肯定是一个会让你有着十分不错成长的一个学习方向,对吧。然后一些自己十分感兴趣,但看起来好像对自己成长并没有帮助的内容和知识,到底要不...


 0
799
09-19 20:10
0
799
09-19 20:10
赤壁古战场(武赤壁)今时今日,许多景区依靠综艺节目中明星们的吸引力来提升自己的知名度,其实这种方式古已有之。虽然没有现代的刻意而为,但是的确存在大量原本无人问津的穷乡僻壤,随着名人效益而声名鹊起的现象。其中最为突出的,大概就是以苏轼为代表的文豪们的造景能力。苏轼所写的《赤壁赋》脍炙人口,“大江东去,浪淘尽,千古风流人物...


 0
524
09-19 20:08
0
524
09-19 20:08